

25 Interview Questions for Data Analyst Role –

Hey Guys, i hope you all are doing well, Today we gonna talk about the general interview questions asked in any Data Analyst Interview.
Data Analyst job role could be the best entry job role for the people who belong to different domains but want to take entry in IT sector or specially Data Science Field.
The job role of data analyst is to understand data in depth and comes with some great visualisations to showcase those depths so that managers/Data Scientists does not have to invest their time in understanding data. We live in a data driven world, all the big companies today takes their decision after analysing data, Every Decision is DATA DRIVEN.
From last few years companies have realised the importance of data in their organisation, that is the reason there is a huge demands for data analyst and data scientist across the globe. But the question is “HOW TO PREPARE FOR DATA ANALYST ROLES?”
Data analyst roles are easy to crack when we compare to data scientist roles, but still you need to give your time and energy to prepare will for these roles.
For Free, Demo classes Call: 020-71173143
Registration Link: Click Here!
Now the question is what topics should we start with…
- BASIC MATHEMATIC- Simple mathematics like linear algebra, simple calculus like Differentiation basics, Integration basic, Vectors calculus, Matrices etc.
- Probability and Statistics-Measure of Central Tendency, Measure of Deviation, Variance, Central Limit Theorem, Inferential Statistics, Hypothesis Testing, A/B testing, Confidence Interval, Z value, Probability Density Function, Cumulative Density Function, Gaussian distribution, Uniform Distribution, Range, Bernoulli and Binomial Distribution, Q-Q Test, Skewness and Kurtosis.
- Exploratory Data Analysis(EDA)- Univariate analysis(Histogram, PDF,CDF, BAR PLOT, BOX PLOT, VIOLIN PLOT), Bivariate analysis(Scatter plot and Pair plot), Multivariate analysis(Contour Plots).
- Data Preprocessing- Scaling of features, Handling categorical features, Handling Missing Values, Handling Duplicates values, Handling null values, One Hot encoding, Label Encoding.
- Natural Language Processing- We need tools like NLTK to handle Text data, Bag of words Vectoriser, TF-IDF Vectoriser, Word2VEC, AverageW2V.
- Dimensionality Reduction- Techniques like PCA(Principle Component Analysis) and TSNE to visualise High Dimension data. Also Understand Curse Of Dimensionality. 7. Some Basics Algorithms- Algorithms like Linear Regression, Logistic Regression, KNN , SVM.
- Miscellaneous Topics- Web Scraping
These are the topics which are generally asked in a interview setup of data analysis.
Let’s Discuss some of the commonly asked questions in Data Analyst Interviews –
Q-1 Write the equation of Hyperplane?
Ans1- Equation of a hyperplane is W^T*X+b=0 , where b is a intercept and this hyperplane does not pass through(0,0).
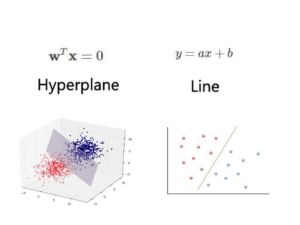
Q-2 Write the equation of Line and Plane?
Ans2- Equation of line is—ax+by=c
Equation of plane is—ax+by+cz=d
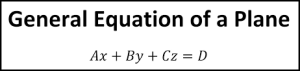
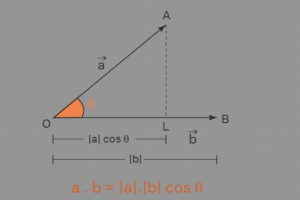
Q-3 What is dot product between 2 vectors?
Ans3- Dot product is, a.b=|a||b|cos(theta)
Q-4 If you have outliers in data, what you will choose as a measure of central tendency, mean or median?
Ans4- Mean is defined as
(SUM OF OBSERVATIONS/NUMBER OF OBSERVATIONS), MEAN as a metric care about the value of individual element because we take a sum of every element and then divide it by number of elements.
for example, lets say i have 5 number in a list,
[1,2,3,4,5], its mean would be Mean=(1+2+3+4+5)/5=3, Mean will be 3
lets add one more number to this list, [1,2,3,4,5,100]
Now it’s mean would be=(1+2+3+4+5+100)/6=19.16, suddenly value of mean move towards the value of 100.
Think about it, mean should be the central value but because of one single value(outlier), mean shifted in that direction so mean is not at all robust to outliers.
On the other hand, median does not take element actual value into account, it just cares about the number of elements in the list, that is why Median is robust to outliers.
For Free, Demo classes Call: 020-71173143
Registration Link: Click Here!
Q-5 Write the formula of standard deviation?
Ans5-

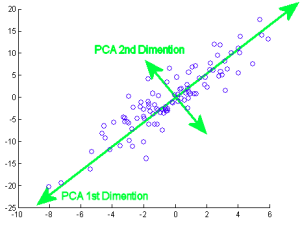
Q-6 What is PCA(PRINCIPLE COMPONENT ANALYSIS)?
Ans6- PRINCIPLE COMPONENT ANALYSIS is a dimensional reduction technique, It works on the principle of maximum variance.
PCA return the direction with the maximum variance.
Q-7 What is Uniform Distribution?
Ans7-In statistics, a type of probability distribution in which all outcomes are equally likely is called Uniform Distribution. For example, when we roll a dice, probability of any outcome(1,2,3,4,5,6) is 1/6. This is called Uniform Distribution.
Q-8 What is the difference between numerical, categorical and ordinal data, give examples?
Ans8- Numerical features simply contains numbers, can be integers, can be decimals.
Categorical feature contains categories like lets say we have a weather feature, which has 3 categories, (Sunny, Overcast and Rainy).
Ordinal features contains categories which has a order in them for example,, let’s say we have a feedback feature and it has three categories-(Average,Good and Very Good) where we have this order.
(Average<Good<Very Good)
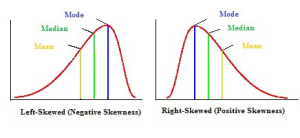
Q-9 What is right skewed and left skewed data ?
Ans9- Picture shows the left and right skewed data.
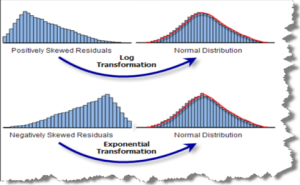
Q-10 What feature transform you should use to transform the right skewed data?
Ans10- We can use log transform to handle the right skewed data.

Q-11 What feature transform you should use to transform the left skewed data?
Ans11- We can use exponential transform to handle the left skewed data.
Q-12 What is Q-Q Test?
Ans12- Q-Q (quartile-quartile) test is used to check if your distribution is Normal or not.
Q-13 What is Univariate Analysis, What are the plot comes under Univariate Analysis?
Ans13- The analysis of a single feature is Univariate Analysis. Univariate plots are-Histogram, pdf, cdf, box plot, violin plot.
Q-14 What is Bivariate Analysis, What are the plot comes under Univariate Analysis?
Ans14- The analysis of two feature together is Bivariate Analysis.
Bivariate plots are- Scatter plot and Pair Plot.
Q-15 What is IQR?
Ans15- IQR stands for interquartile range, It is the difference between 75th percentile and 25th percentile.
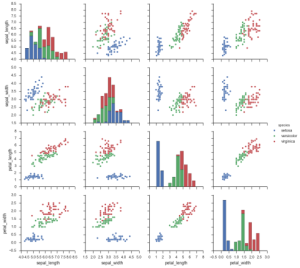
Q-16 What is Pair Plot ?
Ans16- Let’s say in the data i have 4 numerical features so we will have 4c2 scatter plots, that is 6 individual plots, so when we plot all the scatter plot together in one plot that is called Pair Plot.
Q-17 What are the ways to handle missing values in Data Frame?
Ans17- We can handle missing values by just replacing those missing values by Mean/Median of that column if you have less data.
If you have adequate data then you can delete the rows which contains missing values.
For Free, Demo classes Call: 020-71173143
Registration Link: Click Here!
Q-18 What if you have categorical data in data frame, how would you handle it?
Ans18- We have to use One Hot encoding or Label encoding to convert categorical data to numerical data.
Q-19 How would you concatenate two data frames together in python?
Ans19- We have to use pandas library concatenate function to concatenate two data frames.
![]()
In the above example, we are concatenating 2 data frames, first is df_categorical2 and second is df_numerical, we are concatenating through columns, horizontally.
Q-20 How would you count the number of categories in a categorical feature in python?
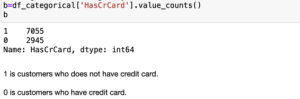
Ans20- So pandas gives us a function called, value_counts() in python, it tells us the number of different categories a feature has, for example,
Lets say we have a bank data and in that data we have a column “HasCrCard”, this column has 2 categories, 1 and 0
0 means the user has credit card
1 means the user does not have credit card,
so i want to check, out of 10k users, how many of them have credit card and how many of them does not have credit card.
Q-21 How would you handle text data in data frame?
Ans21- Machine Learning algorithms understands Numbers, Vectors or matrices depending upon what is the dimensionality of our data but when there are features which consists of text data, let’s say Reviews of a customer then we have to convert that text data to Vectors, We have feature vectoriser like BOW(Bag of Words), TFIDF and W2V(WORD2VECTOR) for this task.
Q-22 What is Curse of Dimensionality?
Ans22- Curse of dimensionality states that if in data number of features are very large in number, then euclidian distance between the individual data points becomes equal in that high dimensional space. So if we use any algorithm which is based on distance then it will give us false results.
Lots of dimensions also makes model very less interpretable.
It also effects the run time complexity of the model, more the features, more the dimensions, more will be the run time complexity of the model.
Q-23 How would you visualise 100 dimensions data set into 2-Dimensions?
Ans23- We can use Techniques like PCA(Principle Component Analysis) which select the direction with maximum variance or we can use TSNE which stands for T distribution Stochastic Neighbourhood Embedding for reducing dimensions.
Q-24 Why do we need Regularisation?
Ans24- Regularisation is needed to overcome overfitting in the model, for example, In logistic Regression, we minimise the sum of signed distance or we minimise the log loss, when we write the log loss mathematically
F(x)=min(log(1+e^(-yi*Wt*xi))), we want to find w which minimise this F(x)
Now if we think about it, log is a monotonic function and the exponential term is always positive, so
log(1+always_positive) will be always positive, so minimum value of F(x) is 0, and w has to be infinite to make F(X)=0 because log(1) is 0, to make this happen, e^(-yi*Wt*xi) has to be 0, for this w has to be infinite.
W is infinite means we want a infinite dimensional hyperplane, to avoid this we add a regularisation term of WTW(W transpose W).
Now F(x) becomes,
F(x)=min(log(1+e^(-yi*Wt*xi))+ lambda(WTW)), Where lambda is a hyperparameter.
For Free, Demo classes Call: 020-71173143
Registration Link: Click Here!
Q-25 What libraries would you use to scrape a website if a page is static?
Ans25- We use libraries like Beautiful Soup for scraping purpose if the page is static, also we use Requests library to get the page we want to scrape.
Thank you for reading, i hope it will help you in preparation.
Author:
Call the Trainer and Book your free demo Class Call now!!!
| SevenMentor Pvt Ltd.
© Copyright 2021 | Sevenmentor Pvt Ltd.