

Data Science Interview Question(TOPIC WISE-PART-2)
Hi guys, This is the second blog of the Interview Question Series where we will discuss the most frequently asked questions in data science interviews and that too topic-wise, At the end of the series you will get around 100–150 questions which you can revise before going to any interview.
Today’s Topic Decision Trees
Question-1 What is a Decision Tree?
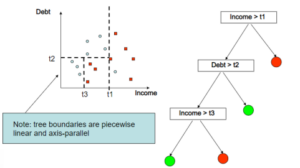
An answer-1 Decision tree can be described in two ways, First way is geometrically and the second way is programmatic.
Geometrically- A Decision Tree is a set of axis-parallel hyperplanes which divides the coordinate plane into cuboids, cubes, hyper-cuboids, and hyper-cubes.
Like in the above example, On the x-axis we have the income feature and on y-axis, we have the Debt feature, the First condition is if income is greater than t1(let’s say 50k) then it will be classified as Red(let’s say eligible for a loan or not).
For Free, Demo classes Call: 020-71173143
Registration Link: Click Here!
So if a person earns more than 50k then he will be eligible for the interview otherwise his debt will be checked.
That one condition created a y-axis parallel hyperplane.
Then we checked if somebody has more than t2 debt(let’s say 10 Lakhs), if somebody got more than 10 lakhs debt then we will check something else otherwise he is approved for the loan and the process goes on.
But the main question is how will get to know the value of t1 or t2 from a wide range of values in the data and secondly how will decide which feature will be the first to break from?
We need concepts like entropy and information gain, we will look in the next questions.
Programmatically- A Decision Tree is nothing but nested if-else statements. Now we have seen it geometrically, let’s see decision trees programmatically. if I write a simple piece of code..
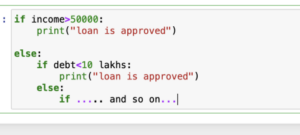
This code shows that the decision tree is nothing but nested if else…
For Free, Demo classes Call: 020-71173143
Registration Link: Click Here!
Question-2 What is Entropy?
Answer 2 Entropy can be said as a measure of randomness. This means is there is more randomness, there is more entropy, if there is less randomness, there is less entropy.
Let me give you an example,
let’s say there is a classroom with 10 people, out of 10, 8 are boys and 2 are girls. You have to randomly pick 4 students out of these 10. Now we know no of boys is more than no of girls, we can easily say that there is more probability of picking boys than picking girls. So here there is less randomness as we can see a bias towards one group so here entropy will be less.
let’s take another example, same classroom but 5 boys and 5 girls, now you have to choose 4 people out of 10. Now the probability of choosing any group is the same so randomness is more, so entropy is more.
let’s see the formula for entropy…
H(Y)= -Summation(P(yi)log(P(yi))
where H is entropy for the random variable Y, and Y could take values y1, y2, y3 and so on… Lets take an example for this also.
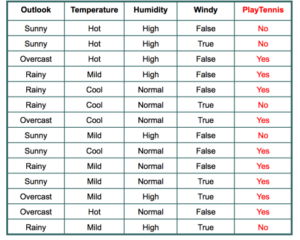
we can see a data here, we have four features
- Outlook 2. Temperature 3. Humidity 4. Windy
Class Label is Play Tennis or Not
So we want to predict that when there are certain weather conditions, guy will play tennis or not.
Now i want to find the entropy of play tennis class label, play tennis has two categories, “yes” or “no”.
H(Play_Tennis)= -(P(yes)log(P(yes) + P(no)log(P(no))
Here P(yes)=9/14 and P(no)=5/14
so, H(Play_Tennis)=-(9/14log(9/14) + 5/14log(5/14))
Question-3 What is information Gain?
Ans-3 Information Gain = (Entropy_of_the parent—Weighted Average Entropy of the child)
We have to find the Information gain for each feature and whichever feature is giving you the maximum information gain will be your first feature to break.
Entropy of the parent is nothing but your class label entropy which we found above.
Weighted Average Entropy of the child= Weighted Average Entropy of one particular feature(feature for which we are finding Information Gain). SevenMentor provides the Best Data Science Course in Pune to master in IT Skills.
Question-4 How to Construct a DT.?
Answer 4. Just find the information gain for every possible feature and the feature which is giving you the best information gain should be the first feature to break from.
For Free, Demo classes Call: 020-71173143
Registration Link: Click Here!
Question-5 How to handle Over-fitting and Under-fitting in DT?
Answer 5. So before talking about overfitting and under-fitting, let’s talk about hyper-parameters, we have “depth of a tree” as a hyper-parameter in the decision tree.
If the depth of the tree is more, the decision tree will capture unnecessary noisy data and will form results near it.
And if the depth of the tree is less(shallow tree), then the decision tree won’t see enough data to make good decisions.
Depth more → Overfitting
Depth Less → Under-fitting.
Practically speaking decision trees are more prone to overfitting so it’s better to take care of depth and tune the hyper-parameter through grid search or random search method.
Thanks for reading…
Author:
Call the Trainer and Book your free demo Class Call now!!!
| SevenMentor Pvt Ltd.
© Copyright 2021 | Sevenmentor Pvt Ltd.