
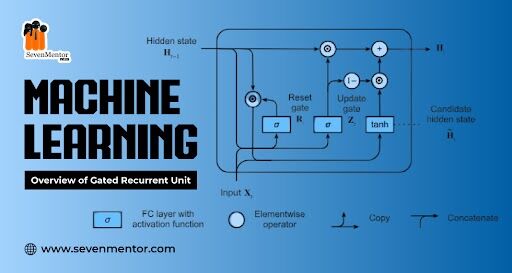
Overview of Gated Recurrent Unit
GRU is a type of Recurrent Neural Network (RNN) that is similar to Long Short-Term Memory (LSTM) networks but with a simpler architecture. GRUs have fewer gates and parameters compared to LSTMs, making them computationally more efficient while still being able to capture long-term dependencies in sequential data. Get an overview of Gated Recurrent Unit (GRU), a simplified neural network model that enhances RNNs for better handling sequential data in machine learning task.
Key Concepts of GRU
- Update Gate: Controls how much of the previous hidden state needs to be passed along to the next step. It combines the forget and input gates of an LSTM into a single gate.
- Reset Gate: Decides how much of the past information to forget, which allows the model to reset its memory when necessary.
- Hidden State: GRUs do not have a separate cell state like LSTMs. Instead, they operate directly on the hidden state, which is updated using the update and reset gates.
GRU Architecture
A GRU cell typically consists of the following components:
- Reset Gate: It is responsible for deciding how much of the past information to forget.
- Update Gate: It determines how much of the current input and the previous hidden state should be passed to the next step.
- New Memory Content: The new candidate memory content is created by combining the reset gate and the current input.
- Final Memory at Time Step: The final memory is a combination of the old memory (controlled by the update gate) and the new candidate memory.
How GRU Works
- Reset Gate: It uses a sigmoid activation function to control how much of the previous hidden state should be ignored. When the reset gate is near 0, the GRU forgets the previous state and starts fresh.
- Update Gate: This gate also uses a sigmoid function and decides how much of the previous hidden state should be passed to the next state. When the update gate is near 1, it passes much of the previous information to the next step.
- Current Memory Content: The reset gate is applied to the previous hidden state to help decide what information to discard. The current input is then combined with this modified hidden state to create the current memory content.
- Final Hidden State: The update gate decides the balance between the previous hidden state and the current memory content, creating the new hidden state for the next time step.
For Free, Demo classes Call: 7507414653
Registration Link: Click Here!
GRU vs. LSTM
- Complexity: GRUs are simpler than LSTMs, having fewer parameters due to fewer gates. This makes GRUs faster to train and more efficient for certain tasks.
- Performance: Both GRUs and LSTMs can perform well, but GRUs may outperform LSTMs in some cases due to their simplicity, while in others, LSTMs may be better at capturing long-term dependencies.
- Usage: GRUs are often preferred when computational efficiency is critical, or when working with smaller datasets.
#how to implement a simple GRU model using TensorFlow’s Keras API. We’ll use the same Airline Passenger dataset for consistency.
#### 1. Import Required Libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import GRU, Dense
In [10]:
#### 2. Load and Preprocess the Dataset
# Load the dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-passengers.csv’ data = pd.read_csv(url, usecols=[1])
# Normalize the data
scaler = MinMaxScaler(feature_range=(0, 1))
data_scaled = scaler.fit_transform(data)
# Define the sequence length
seq_len = 10
# Create sequences and corresponding labels
def create_sequences(data, seq_len):
sequences = []
labels = []
for i in range(len(data) – seq_len):
sequences.append(data[i:i + seq_len])
labels.append(data[i + seq_len])
return np.array(sequences), np.array(labels)
X, y = create_sequences(data_scaled, seq_len)
# Reshape X to be [samples, time steps, features]
X = X.reshape((X.shape[0], X.shape[1], 1))
#### 3. Build the GRU Model
# Build the GRU model
model = Sequential()
model.add(GRU(50, return_sequences=True, input_shape=(seq_len, 1)))
model.add(GRU(50))
model.add(Dense(1))
# Compile the model
model.compile(optimizer=‘adam’, loss=‘mse’)
# Summary of the model
model.summary()
C:\ProgramData\Anaconda3\lib\site-packages\keras\src\layers\rnn\rnn.py:204: UserWarning: Do not pass an `input_shape`/`input_dim` argument to a layer. When using Sequential models, prefer using an `Input(shape)` object as the first layer in the model instead.
super().__init__(**kwargs)
Model: “sequential_1”
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━ ━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━ ━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━ ━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━ ━┩
│ gru (GRU) │ (None, 10, 50) │ 7,950 │
├──────────────────────────────────────┼─────────────────────────────┼ ─────────────────┤
│ gru_1 (GRU) │ (None, 50) │ 15,300 │
├──────────────────────────────────────┼─────────────────────────────┼ ─────────────────┤
│ dense_1 (Dense) │ (None, 1) │ 51 │
└──────────────────────────────────────┴─────────────────────────────┴ ─────────────────┘
Total params: 23,301 (91.02 KB)
Trainable params: 23,301 (91.02 KB)
Non-trainable params: 0 (0.00 B)
In [14]:
#### 4. Train the Model
# Train the model
history = model.fit(X, y, epochs=50, batch_size=32, validation_split=0.2, verbose=1)
Epoch 1/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 4s 173ms/step – loss: 0.1080 – val_loss: 0.1859 Epoch 2/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 21ms/step – loss: 0.0347 – val_loss: 0.0377 Epoch 3/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 27ms/step – loss: 0.0124 – val_loss: 0.0240 Epoch 4/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 24ms/step – loss: 0.0198 – val_loss: 0.0227 Epoch 5/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 21ms/step – loss: 0.0114 – val_loss: 0.0326
Epoch 6/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 28ms/step – loss: 0.0094 – val_loss: 0.0444 Epoch 7/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 21ms/step – loss: 0.0102 – val_loss: 0.0389 Epoch 8/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 26ms/step – loss: 0.0091 – val_loss: 0.0266 Epoch 9/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 33ms/step – loss: 0.0078 – val_loss: 0.0225 Epoch 10/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 26ms/step – loss: 0.0071 – val_loss: 0.0226 Epoch 11/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 23ms/step – loss: 0.0071 – val_loss: 0.0226 Epoch 12/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 24ms/step – loss: 0.0066 – val_loss: 0.0232 Epoch 13/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 20ms/step – loss: 0.0061 – val_loss: 0.0226 Epoch 14/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 32ms/step – loss: 0.0059 – val_loss: 0.0224 Epoch 15/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 35ms/step – loss: 0.0070 – val_loss: 0.0228 Epoch 16/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 25ms/step – loss: 0.0058 – val_loss: 0.0225 Epoch 17/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 25ms/step – loss: 0.0065 – val_loss: 0.0217 Epoch 18/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 26ms/step – loss: 0.0064 – val_loss: 0.0214 Epoch 19/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 25ms/step – loss: 0.0058 – val_loss: 0.0211
Epoch 20/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 29ms/step – loss: 0.0055 – val_loss: 0.0208 Epoch 21/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 19ms/step – loss: 0.0063 – val_loss: 0.0205 Epoch 22/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 31ms/step – loss: 0.0053 – val_loss: 0.0203 Epoch 23/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 22ms/step – loss: 0.0052 – val_loss: 0.0201 Epoch 24/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 31ms/step – loss: 0.0056 – val_loss: 0.0197 Epoch 25/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 22ms/step – loss: 0.0053 – val_loss: 0.0206 Epoch 26/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 28ms/step – loss: 0.0069 – val_loss: 0.0200 Epoch 27/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 41ms/step – loss: 0.0057 – val_loss: 0.0186 Epoch 28/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 29ms/step – loss: 0.0052 – val_loss: 0.0188 Epoch 29/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 37ms/step – loss: 0.0060 – val_loss: 0.0186 Epoch 30/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 29ms/step – loss: 0.0058 – val_loss: 0.0179 Epoch 31/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 39ms/step – loss: 0.0051 – val_loss: 0.0179 Epoch 32/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 23ms/step – loss: 0.0056 – val_loss: 0.0175 Epoch 33/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 21ms/step – loss: 0.0053 – val_loss: 0.0172
Epoch 34/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 31ms/step – loss: 0.0050 – val_loss: 0.0169 Epoch 35/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 27ms/step – loss: 0.0052 – val_loss: 0.0168 Epoch 36/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 20ms/step – loss: 0.0052 – val_loss: 0.0161 Epoch 37/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 27ms/step – loss: 0.0045 – val_loss: 0.0157 Epoch 38/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 35ms/step – loss: 0.0042 – val_loss: 0.0155 Epoch 39/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 27ms/step – loss: 0.0051 – val_loss: 0.0150 Epoch 40/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 22ms/step – loss: 0.0048 – val_loss: 0.0145 Epoch 41/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 23ms/step – loss: 0.0052 – val_loss: 0.0142 Epoch 42/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 28ms/step – loss: 0.0043 – val_loss: 0.0142 Epoch 43/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 28ms/step – loss: 0.0047 – val_loss: 0.0141 Epoch 44/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step – loss: 0.0044 – val_loss: 0.0132 Epoch 45/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 29ms/step – loss: 0.0042 – val_loss: 0.0132 Epoch 46/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 38ms/step – loss: 0.0048 – val_loss: 0.0128 Epoch 47/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 22ms/step – loss: 0.0041 – val_loss: 0.0130
Epoch 48/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step – loss: 0.0047 – val_loss: 0.0126 Epoch 49/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 19ms/step – loss: 0.0047 – val_loss: 0.0117 Epoch 50/50
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 40ms/step – loss: 0.0042 – val_loss: 0.0114 In [15]:
#### 5. Make Predictions and Visualize the Results
# Make predictions
predictions = model.predict(X)
# Inverse scale the predictions and true values
predictions = scaler.inverse_transform(predictions)
y_true = scaler.inverse_transform(y.reshape(–1, 1))
# Plot the predictions against the true values
plt.figure(figsize=(10, 6))
plt.plot(y_true, label=‘True Data’)
plt.plot(predictions, label=‘Predictions’)
plt.title(‘GRU Predictions vs True Data’)
plt.xlabel(‘Time’)
plt.ylabel(‘Passengers’)
plt.legend()
plt.show()
5/5 ━━━━━━━━━━━━━━━━━━━━ 1s 89ms/step
Summary
- GRU Architecture: GRUs use a simpler architecture than LSTMs with fewer gates, which can make them more efficient.
- Model Implementation: The GRU model implementation is similar to the LSTM, but it uses GRU layers instead.
- Performance: GRUs can be more efficient and perform well on many tasks, especially when the dataset is smaller or when computational resources are limited.
Do visit our channel to learn More: Click Here
Author:-
Sagar Gade
Call the Trainer and Book your free demo Class for Machine Learning Call now!!!
| SevenMentor Pvt Ltd.
© Copyright 2021 | SevenMentor Pvt Ltd
